Lokal AI: Hva, hvorfor og hvordan
Hvor er AI-bransjen på vei? Kan AI erstatte utviklere? Vil Skynet være basert på Claude eller Gemini? Vet JARVIS hvor mange «r»-er det er i «strawberry»? Slike spørsmål, kanskje med unntak av de to siste, opptar tankene til de fleste av oss som jobber i IT-bransjen i dag. Dessverre er det også den typen spørsmål som kan klassifiseres som «wicked problems» - umulige å løse eller besvare på grunn av den iboende kompleksiteten i dagens AI-landskap.
Så, hva vet vi?
Om ikke annet, kan vi være sikre på at holdningen vår til AI er i endring. De rosefargede AI-inspirerte brillene som IT-bransjen har hatt på seg de siste årene glir stadig mer av nesen på oss, tynget av økende bekymringer for personvern, sikkerhet og de økonomiske konsekvensene av omfattende innføring av AI.
Disse bekymringene er heller ikke ubegrunnet. For eksempel kunngjorde Copilot nettopp at de endrer prismodellen sin (noe som utvilsomt vil føre til økte kostnader for kundene) [1]. Når det gjelder personvern, er det verdt å merke seg at AI-leverandører uttrykkelig opplyser at de (som standard) trener modellene sine på dataene du legger inn [2, 3]. Og når det gjelder sikkerhet, kan kommende AI som Mythos snart få dramatiske sikkerhetsmessige konsekvenser som vil gjøre bruk av AI til et krav.
Så hva kan vi gjøre? Hvordan veier vi disse bekymringene opp mot det faktum at AI tross alt er et utrolig verdifullt verktøy?
Et spesielt interessant alternativ som svarer på disse utfordringene er lokale AI-modeller, men hvordan kommer man i gang? Og hvor godt fungerer det? For å svare på disse spørsmålene bestemte teamet oss for å prøve det ut, og deler her av våre erfaringer.
Hvorfor kjøre AI lokalt?
Det finnes en rekke grunner til at lokal AI ikke bare er godt egnet til å håndtere utfordringer knyttet til kostnader, personvern og sikkerhet, men også i seg selv er et nyttig supplement eller alternativ til skyløsninger. Her er noen av grunnene:
- Ved å bruke lokale AI-modeller kan vi sikre at dataene som mates inn i maskinen vår, forblir på maskinen vår. Dette er ikke bare en fordel, men en nødvendighet i mange tilfeller der det finnes strenge krav til databeskyttelse.
- Ved å overføre enkle og mindre komplekse oppgaver til en lokal modell, kan vi spare penger, eller ha flere tokens tilgjengelige for de mer komplekse oppgavene.
- Det kan være gunstig for klimaet! Datasentre medfør en reelle kostnader for samfunnet (se: [4, 5]) både når det gjelder behov for stadig ny maskinvare, vannforbruk osv. Hvis vi kan avlaste spørringer til å kjøre lokalt, vinner alle!
- I mange tilfeller kan det være utrolig praktisk, og gi oss muligheten til å bygge, eller i det minste utforske, løsninger som benytter AI for å løse kontinuerlige prosesser, slik som loggovervåkning, som ellers ville blitt for kostbart.
Hvordan kan vi kjøre AI lokalt?
For bare noen få år siden var lokal bruk av AI noe som var forbeholdt institutter, bedrifter og dedikerte entusiaster som hadde råd til å foreta en stor (økonomisk) investering i spesialutviklet maskinvare.
Heldigvis er det her de moderne MacBook-ene med Apple-silicon, som mange allerede har, virkelig kommer til sin rett. Dette er fantastisk maskinvare for å komme i gang med lokale AI-modeller (med noen forbehold, som vi kommer tilbake til nedenfor).
Det finnes flere programmer som gjør det enkelt å utnytte denne muligheten, men her er noen av våre favoritter.
LM Studio

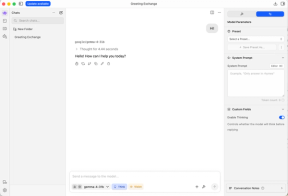
Hvis du er på utkikk etter et alt-i-ett GUI-program, er LM Studio veldig praktisk. Det lar deg:
- Laste ned AI-modeller lokalt til maskinen din
- Konfigurere innstillinger for AI-modeller (for eksempel kontekstvinduer, temperatur, sampling osv.)
- Kommunisere med AI-modeller gjennom den innebygde GUI-chatten. Hvis du laster ned en modell som støtter ‘vision’, støttes også bilde-til-tekst
- Konfigurere et lokalt endepunkt for kommunikasjon med en modell over HTTP.
Ollama
Et annet alternativ er Ollama, som lar deg gjøre omtrent det samme som LM Studio, men via en kommandolinje i stedet. Dette kan kombineres med verktøy som OpenCode for å få et terminalbasert brukergrensesnitt. Ollama er imidlertid langt mer begrenset når det gjelder innstillinger som kan justeres eller konfigureres, og det er derfor jeg foretrekker og anbefaler LM Studio.
En viktig merknad er at Ollama først nylig (30. mars 2026) fikk støtte for MLX, som er et rammeverk for optimalisering av AI-modeller for Mac. Noen har nemlig rapportert om MLX-problemer ved bruk av Ollama på nye M5-Mac-er med macOS Tahoe <26.4.0. Hvis du opplever problemer, må du sjekke om det finnes systemoppdateringer.
Det beste fra begge verdener
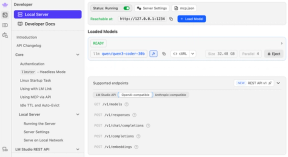
Hvis du ikke ønsker å bruke LM Studio GUI, men likevel vil ha god konfigurerbarhet, finnes det et tredje alternativ (som jeg personlig bruker). Du kan nemlig sette opp en lokal server i LM Studio, og deretter sende kommandoer til den via de innebygde LM Studio, Open-AI kompatible, eller Anthropic-kompatible API-alternativene.

Hvilke AI-modeller kan vi kjøre lokalt?
Ok, så du har valgt din foretrukne applikasjon. Hvilke AI-modeller kan eller bør du kjøre? AI-feltet utvikler seg raskt, og med så mange spesialiserte modeller og bruksområder finnes det ikke noe entydig svar. Og selv om det hadde vært det, ville det vært utdatert allerede når du har lest denne siden.
Derfor er CanIrun en flott ressurs for å få en rask oversikt over hvilke AI-modeller som finnes, og som kan kjøre godt på maskinen din.
Sørg for å velge din CPU, og endre VRAM-alternativet slik at det samsvarer med hva din mac har. Under Tasks kan du også filtrere etter det som er viktigst for deg (vision, koding osv.). Sortering kan også gjøres basert på hastighet, kontekst, parametere og en samlet poengsum. Merk at CanIrun av en eller annen grunn deler rangeringen i to seksjoner, tilsynelatende uten grunn. Bare fordi en modell ligger under en annen i listen, betyr ikke at den er dårligere!
Onyx's selvhostede LLM-rangering er en annen lignende side, som gir mer omfattende rangeringer basert på bruksområde.
Hva er det beste akkurat nå?
Generelt sett er Gemma 4 en av de beste LLM-modellene for allmenn bruk, i hvert fall etter min mening. Men, det finnes mange forskjellgie varianter av Gemma 4, og hvis du ønsker en grundig forklaring kan du se denne bloggposten (avsnittet «Forstå kontekst» nedenfor er i hovedsak en forkortet versjon av innlegget). Jeg ville imidlertid alltid valgt enten 26B A4B eller 31B. Dette skyldes måten de håndterer kontekst på, noe som forklares nedenfor.
Forståelse av kontekst
Når man velger en lokal modell, er konteksten (etter min forståelse) en av de viktigste faktorene – om ikke den aller viktigste – for kvaliteten på svarene man får fra en LLM. Dette gjelder særlig hvis man skal generere eller legge inn store datamengder, for eksempel kode.
Kontekst er i hovedsak en måte å beskrive hvor mye informasjon en modell kan bruke for å danne sitt svar. Hver LLM er laget med et «vindu» av en viss størrelse som rommer en viss mengde informasjon. Dette inkluderer all tekst som er skrevet og generert i en samtale - både dine spørsmål og AI-ens svar. Hvis du er kjent med stackbasert minnetildeling, vil dette virke kjent.
Generelt sett gjelder det at jo større vinduet er, jo mer informasjon beholder modellen i minnet, noe som gir deg bedre svar siden den kan bruke mer av sin kunnskap om hele samtalen dere har hatt. For Gemma 4 har E2B og E4B et glidende vindu på 512 tokens, mens 26B A4B og 31B har et glidende vindu på 1024 tokens.
Størrelse er imidlertid ikke alt. For det første bruker ulike modeller (og varianter av modeller) denne konteksten på forskjellige måter, og for det andre vil alle modeller gå tom for minne. Når dette skjer, kan modellene dele konteksten inn i flere lag, hvert med et eget sett med informasjon i et glidende vindu.
Hvordan disse lagene kombineres, er det som i stor grad bidrar til kvaliteten. I Gemma sitt tilfelle, så kombinerer 31B omtrent 60 lag for et svar (dvs. ved å bruke flere glidende vinduer), mens de andre kombinerer rundt 30–42.
Tips og triks for å optimalisere ytelsen
Når du velger en modell å laste ned i LM Studio, har du (avhengig av modellen) ofte muligheten til å laste den ned i enten GGUF- eller MLX-format. Velg MLX, da dette formatet er optimalisert for Apple Silicon.
I tillegg bør du sette Mac-en din i High Power-modus når du bruker lokale modeller! Batterilevetiden vil bli redusert, men ytelsen blir betydelig bedre. Jeg har kjørt noen (helt uvitenskapelige) tester, og High Power-modus på min M5 Max halverer omtrent tenketiden for små prompter, sammenlignet med Low Power. Ikke stol på automatisk modus heller, da den også begrenser strømforbruket sammenlignet med High Power-modus!
Hvis du virkelig vil maksimere rå ytelse, må du sørge for å bruke laderen som fulgte med Mac-en din, i stedet for å stole på strøm fra en ekstern kilde. Anekdotisk la jeg merke til under testing at når jeg strømforsynte Mac-en min via en skjerm ved hjelp av Thunderbolt 4, var ytelsen omtrent 5–10 % lavere i generelle CPU-benchmarks, sammenlignet med når jeg brukte laderen.
Tips og triks for LM Studio
Noen AI-modeller (spesielt Gemma 4) kan raskt fylle opp hele kontekstvinduet med bare ett prompt/svar, selv med de innstillingene som 31B bruker for å maksimere størrelsen. Dette vil føre til at modellen går i sirkel eller gir dårlige svar, da den ikke klarer å holde tidligere spørsmål/svar i minnet. Dette er noe som må evalueres nærmere, men tre «løsninger» er som følger:
- Gå til «My Models», velg modellen du bruker, og velg deretter «Load» i sidefeltet. Der kan du justere kontekstlengden.
- I samme meny, hvis du blar litt lenger ned, finner du alternativet «KV Cache Quantization» eller «Unified KV cache» (nøyaktig hvilke alternativer du kan velge mellom, avhenger av hvilken modell du har lastet inn). Hvis du deaktiverer disse, kan hver prediksjon bruke hele kontekstlengden, men dette krever mer minne. Dette alternativet ser ut til å løse problemer med kontekst og kvalitet i enkelte modeller, for eksempel Gemma 4.
- I samme sidefelt går du til «Inference». I systemmeldingsboksen legger du til noe i stil med «Hold alle svarene korte og konsise». Dette bør holde modellen mer begrenset, slik at kontekstbruken reduseres, samtidig som kvaliteten holdes god.
For modeller som støtter tenkning, er dette aktivert som standard, men kan deaktiveres enten under «Custom Fields» i sidefeltet «Model Parameters», eller ved å trykke på tenke-knappen i tekstfeltet i en samtale.
Lokal AI-clusters
Selv om det å kjøre lokal AI på én maskin kan dekke behovene til de fleste brukere svært godt, og justeringene som er omtalt ovenfor kan hjelpe deg med å optimalisere ytelsen enda mer, finnes det likevel situasjoner der én enkelt datamaskin rett og slett ikke klarer å oppfylle kravene våre.
Vi har for eksempel merket denne ulempen i situasjoner der vi trengte å gi AI-en en svært stor mengde kontekst (for eksempel når vi forsøkte å legge inn en hel kodebase, eller når vi endret/opprettet svært store JSON-filer).
Exo
Det er her verktøy som Exo kommer inn i bildet, og lar oss opprette lokale AI-klynger ved hjelp av flere maskiner. Exo har en rekke flotte funksjoner, blant annet:
- Forhåndskompilerte MacOS-bilder som gjør installasjonen til en lek,
- En integrert modellnedlaster som også bruker maskinvaredeteksjon for å filtrere,
- Flere API-grensesnitt for kommunikasjon med klyngen,
- Og viktigst av alt: Støtte for RDMA, en funksjon som lar (M5- eller M4 Max-) Mac-er samle minne via en forbindelse med svært lav ventetid.
Vår konfigurasjon
Vi satte opp vår egen cluster ved hjelp av tre MacBook Pro M4 Max-maskiner (hver med 64 GB RAM), koblet sammen via Thunderbolt 5 slik at vi kunne benytte RDMA. Etter å ha gjort dette og fulgt konfigurasjonsinstruksjonene for både RDMA og Exo, ble maskinvaren automatisk gjenkjent, og klyngen ble opprettet automatisk!


Tilgang til Exo
Exo har som standard et dashbord (som vises på datamaskinen i midten) som er tilgjengelig for alle enheter i klyngen. Dette dashbordet lar deg starte en AI-instans, kommunisere direkte med den via den innebygde chatten, samt gir oversikt over de tilgjengelige API-endepunktene du kan bruke til å kommunisere med klyngen.
Selv om det er enkelt å få tilgang til datamaskiner som kjører Exo i et lokalt nettverk, ønsket vi å kunne få tilgang til dem uansett hvor vi befant oss. Derfor installerte vi Tailscale på en av enhetene i klyngen. Dette, sammen med en rask 3D-print av en stand, gjorde at vi kunne få et ryddig oppsett:


Bruk av Exo fra en ekstern maskin
Generelt sett var opplevelsen av å bruke Exo fra en ekstern maskin ganske problemfri. Det ga oss et svært godt lokalt AI-oppsett til daglig bruk, samtidig som det sikret oss god ytelse til andre formål på våre personlige maskiner.
Vi prøvde å bruke klyngen på en rekke forskjellige måter. Først prøvde vi Open WebUI, som ga oss en veldig praktisk, nettleserbasert chat-klient. Dette fungerte bra, selv med flere brukere koblet til klyngen samtidig. Å kalle API-et direkte i koden viste seg også å være enkelt – i stor grad på grunn av at Exo har API-endepunkter som er kompatible med OpenAI, Claude og Ollama.
Den største fordelen vi fant med Exo, var at vi hadde hele 192 GB RAM til rådighet. Sammenlignet med å kjøre en modell lokalt på én maskin, gjorde dette at vi kunne legge inn enorme mengder data i modellen og få ut enorme mengder. Dette var spesielt nyttig, for eksempel når vi ønsket å gi modellen vår en hel (produksjons)kodebase på en gang, noe som ga den en bedre forståelse av koden sammenlignet med å lese inn én fil om gangen.
Exos svakheter
Det finnes imidlertid en rekke svakheter ved Exo, noe som i stor grad skyldes at dette er et brukerdrevet prosjekt som fortsatt er i en tidlig utviklingsfase.
Det største problemet vi støtte på, var at enkelte modeller (spesielt MiniMax-M2.7-5bit) kan føre til merkelige problemer, blant annet avbrutte økter og problemer med å bytte til andre modeller.
Et annet problem er hvordan Exo håndterer sharding (arbeidsfordeling). Tensorparallellisme oppnås nemlig ikke når man bruker et partall av enheter (kun pipeline), noe som betyr at mye ytelse foreløpig går tapt.
Avsluttende tanker
For omtrent tre og et halvt år siden lanserte OpenAI ChatGPT for publikum. Da jeg aldri hadde brukt en LLM før dette, ble jeg sjokkert over hvor bra det fungerte. Visst hadde det sine mangler, men man kan ikke benekte at det endret hvordan mange av oss tenkte om fremtiden.
I dag kan du laste ned en lavnivåmodell og kjøre den helt offline, på en datamaskin med 4 kjerner og 16 GB RAM, gratis, og få bedre resultater.
Hvis ikke det begeistrer deg, vet jeg ikke hva som vil gjøre det.

