Erfaringsbrev fra sommerstudentene hos Spleis!
Spleis åpner dørene for mange gode initiativer, men hvordan fanger vi spleisene som ikke burde slippe gjennom? I sommer har vi laget et system som er skarpt nok til å sende de usikre prosjektene til manuell vurdering, samtidig som det lar gode prosjekter fly rett gjennom.
Kort om oss
Hey👋, vi er Magnus og Tobias, Datateknologi-studenter ved NTNU. Vi har fullført henholdsvis fjerde og tredje studieår, og spesialiserer oss begge på KI. Som Data & Analyse sommerstudenter, har vi fått sjansen til å hjelpe Spleis med å forbedre godkjennings-systemet sitt. Underveis har vi lært mye og fylt opp lommene med erfaringer. Nå gleder vi oss til å tømme dem og dele alt med dere!🤩
Først og fremst, hva er Spleis?
Spleis fra Sparebank 1 er en folkefinansieringstjeneste, der kan man samle inn penger til hva man vil! Eller... nesten hva man vil. Blant tusenvis av positive og lovende spleiser, finnes dessverre noen få som ikke burde se dagens lys. Dette kan være spleiser som bryter med retningslinjene, for eksempel ved å fremstille barn på uheldige måter, samle inn penger til ulovlige formål, eller rett og slett har for mye usikkerhet rundt formålet eller mottakeren. Vår oppgave har vært å godkjenne de legitime spleisene og luke ut dem som krever nærmere vurdering.
Så, hvordan går man frem for å lage et slikt system? Da må vi starte med å se på hva en spleis består av: Innsamleren kan formidle budskapet sitt med både tekst og bilder. De må ha et reelt innsamlingsmål, i tillegg til å bestemme seg for om det skal doneres til en organisasjon, noen andre eller seg selv. Alt dette er med på å gi oss et bilde av hva slags spleis vi har med å gjøre – og akkurat det trenger systemet for å kunne ta gode valg.
Du tenker kanskje det samme som vi tenkte de første dagene – "Dette er jo perfekt for en språkmodell! Vi bare mater inn spleisen sammen med brukervilkårene og så finner den regelbruddene!" – Men med skuffende resultater, fant vi fort ut at spleis-klassifisering trengte en mer systematisk approach.
Systemet vårt må "tenke" som Operations
Operations er avdelingen som følger opp en spleis gjennom hele livsløpet - fra godkjenning ved publisering og frem til den vurderes på nytt før eventuell utbetaling. Her tas vurderinger ofte på grunnlag av domenekunnskap og menneskelig skjønn, det kan være alt fra å avsløre tullespleiser til å gjenkjenne saker knyttet til barnefordeling. Alt dette gjør oppgaven svært nyansert og vanskelig for én enkelt språkmodell å løse pålitelig. For å kunne ta hensyn til de ulike aspektene Operations vurderer, gikk vi for en Mixture-of-Experts tilnærming med forskjellige språkmodeller: én som fokuserer på domenekunnskapen, én som ser på brukervilkår og én som vurderer tilfellene hvor det er barn i bildene til spleisen.
Samtidig er over 95% av spleiser helt trygge, da blir det fort dyrt å utelukkende basere seg på språkmodeller for å kun fange opp 5% av spleisene. I tillegg sitter Spleis på mye nyttig data som vi ikke får bruk for dersom vi bare bruker språkmodeller. Derfor er det ideelt å kunne trene en klassifiseringsmodell som kan rydde unna de mest åpenbare, trygge spleisene i første runde, for så videresende de mer nyanserte spleisene til språkmodellene. Men hvis vi skal trene en klassifiseringsmodell, er vi nødt til å ha en "fasit". Heldigvis blir alle spleiser sjekket av et menneske før den utbetales, og beslutningen som gjøres her kan vi da bruke til å bedømme om spleisen er bra eller dårlig.
Systemet vi endte opp med
Vi bestemte oss for å lage et prediksjons-system bestående av flere komponenter: én klassifiseringsmodell, språkmodeller, bilde-klassifiseringsmodell og et enkelt ord-flagge system. Vi kobler disse sammen slik.

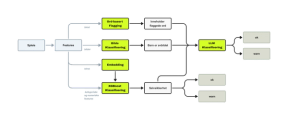
- Klassifiseringsmodellen vi bruker er XGBoost. Denne er trent på embeddings av teksten i spleisene, i tillegg til innsamlingsmål, innsamler og mottaker. Vi trente den på et balansert, undersamplet treningssett på ca 3000 spleiser (50/50 godkjent / ikke godkjent), og fikk gode resultater allerede her.
- Bilde-klassifiseringsmodellen består av to modeller: én som detekterer ansikter (MTCNN) og én som predikerer alderen på et ansikt (SigLIP-2-Age-Classification). Slik kan vi scanne bildet for ansikter, og få gode prediksjoner på om barn blir eksponert på bildet.
- Flagge-systemet er enkelt, det har en liste med svartelistede ord, hvis noen av disse forekommer i teksten, sendes spleisen alltid videre til språkmodell-klassifisering.
Grovarbeidet gjøres altså først av XGBoost, flagge-systemet og bilde-klassifiseringsmodellen. Er disse alle veldig sikre på at det ikke er noe ugler i mosen, vil det kunne returneres ok allerede her. Hvis noen av modulene derimot signaliserer at spleisen burde gjennom en grundigere sjekk, vil den sendes til den språkmodell-baserte klassifiseringsmodellen. Den ser slik ut:

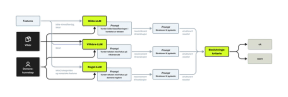
- Bilde LLM'en trigges kun hvis det er mistanke om barn i bildet, her sjekkes det om den tekstlige konteksten er uheldig for barnet å bli assosiert med
- Vilkårs LLM'en passer på at spleisene følger Spleis sine vilkår, og sier ifra om hvilke som blir brutt.
- Regel LLM'en får et sett med regler som den skal følge, slik kan vi bake inn spesifike instrukser som ikke omhandler vilkårene direkte.
For at en spleis skal godkjennes, må det være felles enighet blant disse tre språkmodellene. Hvis minst én er i tvil, sendes spleisen til et menneske.
Funker dette, da?
Systemet har vist seg å fungere veldig bra! Med det nye systemet sendes kun 10% av gyldige spleiser til manuell godkjenning, dette er en stor forbedring fra 60% (slik det er i dag). I tillegg gir språkmodellene også en skriftlig forklaring på valget sitt, det er et godt utgangspunkt for Operations når de skal gjøre en videre vurdering. Nå som også bildene blir analysert, har vi også fått på plass et enda bredere sikkerhetsnett som beskytter barn mot uheldig bildedeling på Spleis. Alt i alt, har vi laget et system som gjør jobben enklere for Operations og tryggere for alle som bruker Spleis.
Har det gått på skinner?
Nja, det har gått ganske smooth, men noen blockers har det vært:
- Aaaaaa-synkrone requests: XGBoost-modellen brukte knapt et sekund på å predikere, mens språkmodellene brukte evigheter i forhold. Løsningen ble en mer tålmodig, callback-arkitektur.
- Token-sjokk: Vi trodde et steg av språkmodell-systemet skulle produsere maks 200 tokens, men den prøvde å spytte ut 32 000. Heldigvis fikk vi en feilmelding på dette før regningen vokste seg skyhøy.
- 13x for stor app: Planen var å hoste API'et et sted der applikasjoner er begrenset til 500MB i størrelse. Ved vår første containerization: 6.84GB - dette var jo litt skivebom. Etter å ha droppet PyTorch sine GPU-pakker og ryddet skikkelig, deployet vi containeren på AWS i stedet (endte opp på 1.2GB).
- Dårligere resultater med RAG: Vi testet ut RAG, men uten forklaringer i dataene ble modellen bare forvirret – så den ideen havnet til slutt på hylla.
- Prompt engineering: Det høres enkelt ut, men å skrive gode prompts er faktisk en kunst i seg selv.
Uansett om vi har hatt motvind eller medvind, har vi fått masse ny kunnskap om: embeddings, klassifiseringsmodeller, metrikker, langchain, pydantic, RAG, docker, aws, github-workflows, transformers, bilde-modeller, lisenser, mlflow og asynkrone-arkitekuter. Det har vært mye nytt å sette seg inn i, men enda mer å ta med seg videre.
Hva vi sitter igjen med
Prosjektet hos Spleis har vært veldig gøy, her har det vært lite føringer og masse frihet til å eksperimentere, feile og lære. Nå sitter vi igjen med et system vi begge er stolte av. Det er stas å se hvordan man kan kombinere av forskjellige områder av maskinlæring til å lage et system som skaper verdi i praksis. Men det vi virkelig setter aller mest pris på, er hvordan systemet nå beskytter barn som havner i sårbare situasjoner – vi har troen på at det skal komme mobbere og bekjente i forkjøpet ❤️
Del kunnskapen
Har du en kollega som også hadde dratt nytte av denne artikkelen?




Relevant innhold
Her finner du innhold i samme gata om du vil lære mer.






Mer fra Fag i Bekk
Nå er du ved veis ende. Gå til forsiden hvis du vil ha mer faglig påfyll.
Til forsiden