Datadreven evaluering av prompt og svarkvalitet i LLM-systemer
I denne artikkelen viser vi hvordan du kan måle, sammenligne og versjonere LLM-eksperimenter, slik at forbedringer blir datadrevne og reproduserbare i stedet for basert på magefølelse.
Har du noen gang deployet en ny promptversjon til produksjon og håpet på det beste? Enten du justerer en prompt, bytter embedding-modell eller tweaker retrieval strategien i et RAG-oppsett, er det vanskelig å vite hva som faktisk gir bedre kvalitet uten systematisk evaluering. Man kommer kanskje opp til et akseptabelt nivå, men når ytelsen flater ut blir det desto vanskeligere å få et klart svar på hvilke faktorer som begrenser kvaliteten, uten gode rutiner for evaluering. Da blir videre forbedring ofte vanskeligere, tregere og mer risikable.
Hvorfor er LLM-evaluering vanskelig?
I motsetning til tradisjonell maskinlæring, hvor vi trener modeller og optimaliserer mot én eller flere metrikker, er generativ AI vanskeligere å kvantifisere. Vi predikerer ikke numeriske verdier og sitter sjelden med en entydig fasit.
Ta et kundesupportssvar fra en LLM: Er svaret "godt" hvis det er korrekt men upersonlig? Hvis det dekker alle detaljer men er for langt? Eller hvis det er vennlig og kort, men glemmer å nevne en viktig begrensning? Det finnes ingen enkelt accuracy-metrikk som fanger dette.
Kvalitetskriterier er ofte subjektive. Preferanser varierer, og det finnes mange ulike måter å gi et riktig svar på. Likevel er det stor verdi i å strukturere måten vi evaluerer på. Ved å bruke faste testdata, automatiserte metrikker og versjonskontroll kan vi gjøre LLM-utvikling mer systematisk. Det er store gevinster å hente når vi kan måle forbedringer objektivt i stedet for å stole på enkeltvurderinger.
MLflow for LLM-evaluering
MLflow har lenge vært et standardverktøy for å spore maskinlærings-eksperimenter, men har de siste årene også blitt godt egnet for generativ AI. Med funksjoner som Prompt Registry, LLM-as-judge scorers og automatisk trace-logging kan vi nå evaluere LLM-systemer på samme strukturerte måte som tradisjonelle ML-modeller.
I denne artikkelen bruker vi MLflow til å evaluere et juridisk RAG-system, men prinsippene gjelder uansett domene. Eksemplene bygger på en MLflow-instans deployet i GCP (beskrevet i denne artikkelen), men kan også kjøres lokalt eller i andre skymiljøer. Eksempelkoden for oppsett og evaluering ligger her.
For å evaluere trenger vi et sett med gullstandard
Dette er tidkrevende arbeid, men helt nødvendig for å gjøre gode evalueringer.
Hvordan testdataene utformes avhenger av bruksområde og hva du ønsker å teste. I dette eksempelet ser vi for oss et system som svarer på brukerens spørsmål basert på egne dokumenter hentet gjennom en retrieval-prosess.
Selve datauthentingen er interessant å evaluere i seg selv, men her ønsker vi å isolere prompten som variabel. Ved å bruke det samme datagrunnlaget hver gang kan vi måle hvordan endringer i prompt og instruks påvirker kvaliteten på svarene.
Tenk deg et internt juridisk verktøy som presenterer aktuelle lover, og tidligere saker og tolkninger. Systemet skal ikke konkludere, men gi et godt grunnlag for vurdering. Det betyr at både relevans, presisjon og evnen til å trekke frem motstridende informasjon er viktige kvalitetskriterier.
For å evaluere dette trenger vi et datasett med:
- Realistiske problemstillinger (spørsmål fra faktisk bruk)
- Forhåndsdefinerte kilder (de dokumentene systemet skal svare basert på)
- Forventet svar (fasit som representerer ønsket kvalitet)
Uten et slikt datasett blir evalueringen i stor grad tilfeldig.
EVAL_DATA = [
{
"inputs": {
"question": "Et samboerpar har flyttet fra hverandre og overfører hjemmel på felles bolig. De har hatt felles folkeregistrert adresse i ett år. Har de krav på fritak for dokumentavgift?",
"related_docs": [
{
"id": "lovdata",
"text": "Ved samlivsbrudd mellom samboere kan det gis fritak for dokumentavgift når eiendommen har vært partenes felles bolig og de har hatt felles folkeregistrert adresse i minst to år.",
"source": "Dokumentavgiftsloven § 8"
},
{
"id": "v1",
"text": "Kravet om to års felles folkeregistrert adresse er absolutt. Feil hos tredjeparter gir ikke grunnlag for fritak.",
"source": "Vurdering 06.01.2026"
},
{
"id": "v2",
"text": "Samboere som ikke oppfyller kravet om to års felles folkeregistrert adresse får ikke fritak, selv om de har bodd sammen i utlandet.",
"source": "Vurdering 06.01.2026"
},
{
"id": "v3",
"text": "Dersom samboere tidligere har oppfylt kravet og senere flytter sammen igjen for en kort periode, kan fritak likevel gis.",
"source": "Vurdering 20.10.2025"
}
]
},
"expectations": {
"answer": "Dokumentavgiftsloven § 8 krever minst to års felles folkeregistrert adresse for fritak. Dette er lagt til grunn i flere vurderinger, blant annet i Vurdering 06.01.2026 og Vurdering 20.10.2025. I denne saken har samboerne bare hatt felles adresse i ett år, og vilkåret er ikke oppfylt. Det gis derfor ikke fritak for dokumentavgift."
}
}
]Metrikker for å evaluere LLM
For dette bruksområdet ønsker vi metrikker som fanger både kvaliteten på resonneringen og hvor godt svaret er forankret i kildene. Det er viktig at svaret viser til relevante vurderinger og lovtekst, og at alt som inkluderes faktisk er støttet av dokumentene.
Vi starter med en enkel objektiv metrikk som gir en rask pekepinn på om svaret ligner fasiten.
A. Objektiv metrikk: Cosine similarity
Hva måler den:
Semantisk likhet mellom generert og forventet svar, basert på embeddings fra samme modell som brukes i vector-søk.
Fordeler:
- Rask og deterministisk
- Fanger opp semantisk likhet selv med ulike formuleringer
Ulemper:
- Fanger ikke faktafeil
- Kan gi høy score selv om viktige poenger mangler
MLflow bruker @mlflow.genai.scorers.scorer decorator for å gjøre funksjoner om til standardiserte metrikker:
import numpy as np
import google.generativeai as genai
def get_embedding(text: str) -> np.ndarray:
"""Generer embedding med Gemini."""
result = genai.embed_content(
model="gemini-embedding-001",
content=text,
task_type="retrieval_document"
)
return np.array(result['embedding'])
@mlflow.genai.scorers.scorer
def semantic_similarity(inputs: dict, outputs: str, expectations: dict) -> float:
"""Cosine similarity mellom generert og forventet svar."""
generated_emb = get_embedding(outputs)
expected_emb = get_embedding(expectations.get("answer", ""))
# Cosine similarity
similarity = np.dot(generated_emb, expected_emb) / (
np.linalg.norm(generated_emb) * np.linalg.norm(expected_emb)
)
# Skaler til 0-5
return float(similarity * 5)B. Subjektive metrikker: LLM-as-judge
Her bruker vi en LLM til å vurdere svarene fra en annen LLM. Dette gjør det mulig å evaluere mer subjektive kvalitetskriterier som relevans, forankring i kilder og faglig korrekthet.
Eksempel på metrikker:
- Relevans: Svarer svaret på spørsmålet?
- Groundedness: Er påstandene forankret i dokumentene?
- Correctness: Stemmer vurderingen med forventet fasit?
# Psuedokode for svargenerering, som viser eksempel på flyt
# I produksjon er det gunstig å legge til strengere evaluering av output.
# Parametere som 'response_mime_type' og 'response_schema' i Google Genai eller tilsvarende i andre API'er
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
def ask_llm_for_score(prompt: str) -> float:
"""Spør LLM om score mellom 0-5."""
model = genai.GenerativeModel("gemini-2.5-flash")
response = model.generate_content(
prompt,
generation_config=genai.GenerationConfig(temperature=0.0)
)
# Ekstraher tall fra svar
text = response.text.strip()
for char in text:
if char.isdigit():
return float(char)
return 0.0
@mlflow.genai.scorers.scorer
def relevance_score(inputs: dict, outputs: str, expectations: dict) -> float:
"""Vurder hvor relevant SVAR er for SPØRSMÅL."""
prompt = f"""Vurder hvor relevant SVAR er for SPØRSMÅL på en skala fra 0 til 5.
SPØRSMÅL: {inputs['question']}
SVAR: {outputs}
Svar kun med et tall mellom 0 og 5."""
return ask_llm_for_score(prompt)
@mlflow.genai.scorers.scorer
def groundedness_score(inputs: dict, outputs: str, expectations: dict) -> float:
"""Sjekk om svaret er forankret i kildedokumentene."""
context_parts = []
for doc in inputs.get("related_docs", []):
context_parts.append(f"[{doc['source']}]\\n{doc['text']}")
context_str = "\\n\\n".join(context_parts)
prompt = f"""Vurder om SVAR kun inneholder påstander som er forankret i KONTEKST (0-5).
KONTEKST:
{context_str}
SVAR: {outputs}
Svar kun med et tall mellom 0 og 5."""
return ask_llm_for_score(prompt)Vi kombinerer metrikker for å få et mer helhetlig bilde. Cosine similarity gir en rask sjekk på semantisk likhet, mens LLM-baserte vurderinger evaluerer kvaliteter som krever forståelse av kontekst og resonering. Ingen enkelt metrikk er perfekt, men sammen gir de et solid grunnlag for å sammenligne ulike prompt-versjoner.
Hvordan versjonerer vi prompts?
Hvorfor versjonere prompts:
For at evalueringene skal være reproduserbare må også promptene behandles som kode. Vi vil kunne svare på spørsmål som hvilken versjon som ga best kvalitet, og hvilken som kjører i produksjon akkurat nå.
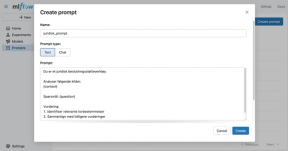
MLflow har et eget Prompt Registry som gjør det mulig å lagre, versjonere og gjenbruke prompts på samme måte som modeller.
Registrere første versjon
Lagre prompt i MLflow:
import mlflow
prompt_template = """Du er et juridisk beslutningsstøtteverktøy.
Kilder:
{context}
Spørsmål: {question}
Gi et vurderingsgrunnlag basert på kildene. Vis til relevante paragrafer og tidligere vurderinger."""
# Logg prompt til registry
mlflow.genai.log_prompt(
artifact_path="juridisk_prompt",
prompt=prompt_template
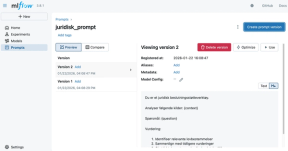
)Når vi senere gjør endringer i prompten, logger vi den på nytt med samme navn. MLflow oppretter automatisk en ny versjon:
# Forbedret prompt med bedre struktur
improved_prompt = """Du er et juridisk beslutningsstøtteverktøy.
Analyser følgende kilder:
{context}
Spørsmål: {question}
Vurdering:
1. Identifiser relevante lovbestemmelser
2. Sammenlign med tidligere vurderinger
3. Gi et faktabasert grunnlag for beslutning"""
mlflow.genai.log_prompt(artifact_path="juridisk_prompt", prompt=improved_prompt)
# Dette blir automatisk versjon 2
I evalueringen kan vi nå spesifikt velge hvilken versjon vi vil teste:
# Last versjon 2
prompt = mlflow.genai.load_prompt("prompts:/juridisk_prompt/2")
system_message = prompt.format()
Dette kan også gjøres i GUI-et i MLflow, og gjør prompts og eksperimentering med ulike versjoner enklere tilgjengelig, også for de som jobber like kode-nært.


Med versjonerte prompts på plass kan vi nå kjøre evalueringer som automatisk henter riktig versjon og sammenligner resultater på tvers av iterasjoner.
Kjøre en evaluering med versjonert prompt opp mot testdata
Når vi har både gullstandard-datasettet og en versjonert prompt, kan vi kjøre en full evaluering.
PromptEvaluator-klassen kapsler hvordan vi bygger meldinger til modellen og hvordan svaret genereres. MLflow bruker predict()-metoden til å generere svar for hvert eksempel i datasettet på en konsistent måte.
import google.generativeai as genai
import mlflow
genai.configure(api_key="YOUR_API_KEY")
class PromptEvaluator:
def __init__(self, prompt_name: str, version: int = None):
"""Last prompt fra MLflow Registry."""
# Last prompt fra registry
if version:
prompt_uri = f"prompts:/{prompt_name}/{version}"
else:
prompt_uri = f"prompts:/{prompt_name}/latest"
prompt_obj = mlflow.genai.load_prompt(prompt_uri)
self.system_prompt = prompt_obj.format()
self.model = genai.GenerativeModel("gemini-2.5-flash")
def predict(self, question: str, related_docs: list[dict]) -> str:
"""Generer svar basert på spørsmål og dokumenter."""
# Bygg kontekststreng fra dokumenter
context_parts = []
for doc in related_docs:
context_parts.append(f"[{doc['source']}]\\n{doc['text']}")
context_str = "\\n\\n".join(context_parts)
# Formater prompt med kontekst og spørsmål
formatted_prompt = self.system_prompt.format(
context=context_str,
question=question
)
# Generer svar
response = self.model.generate_content(
formatted_prompt,
generation_config=genai.GenerationConfig(
temperature=0.0,
max_output_tokens=2048
)
)
return response.text.strip()Kjøre evalueringen
MLflow genererer svar for hvert eksempel i datasettet, beregner alle metrikker og logger resultatet i ett eksperiment:
evaluator = PromptEvaluator(prompt_name="juridisk_prompt", version=2)
results = mlflow.genai.evaluate(
data=EVAL_DATA,
predict_fn=evaluator.predict,
scorers=[
semantic_similarity,
relevance_score,
groundedness_score,
correctness_score
]
)
print(results.metrics)
# {
# 'semantic_similarity/mean': 4.2,
# 'relevance_score/mean': 4.5,
# 'groundedness_score/mean': 4.8,
# 'correctness_score/mean': 4.3
# }I MLflow UI kan vi nå sammenligne ulike prompt versjoner side for side. Det gjør det mulig å se hvilke endringer som faktisk forbedrer kvaliteten, og hvilke som gjør den dårligere.
Dette gir oss en konkret arbeidsflyt for å iterere på LLM systemer på en strukturert og etterprøvbar måte.

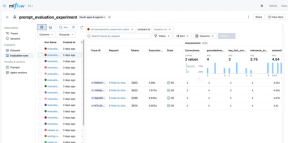
Hver gang vi kjører et eksperiment med en ny versjon av prompten, kan vi sammenligne metrikker mot tidligere kjøringer. Dette gir oss et datadrevet grunnlag for å bestemme om vi skal gå videre med endringen eller rulle tilbake.

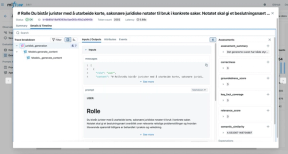
For hvert spørsmål får vi detaljert informasjon om inputdata, hvilken promptversjon som ble brukt, modellens svar og alle metrikker for kjøringen.
Konklusjon
Når vi bygger LLM-systemer er det lett å ende opp med en arbeidsflyt der endringer vurderes på intuisjon. En ny prompt føles bedre, et nytt retrieval-oppsett virker riktigere, men uten systematisk evaluering vet vi ikke om kvaliteten faktisk har blitt bedre.
I denne artikkelen har vi vist hvordan du kan etablere en strukturert evalueringsflyt med faste testdata, tydelige metrikker og sporing av eksperimenter i MLflow. Det gir deg et konkret rammeverk for å iterere på prompts og RAG-oppsett på en måte som er reproduserbar og etterprøvbar.
Det holder å starte enkelt. Lag 5-10 evalueringseksempler for ditt viktigste use case, definer 2-3 metrikker som fanger kvalitetene du bryr deg om, og kjør din første evaluering. Kompleksiteten kan bygges på over tid, men allerede med et lite datasett får du verdifull innsikt i hva som faktisk virker.
Med denne arbeidsformen blir forbedringer i LLM-systemet automatisk mer datadrevne og etterprøvbare.
Lenker

