<ForrigeUke uke="19" år="2026" />
Dette var uken for relaterbare diskusjoner 🗣️, brannsikkerhet 🔥 og etiske dilemmaer 🤔 — og 748 ting som skjedde i frontend-verdenen
«<ForrigeUke /> er en artikkelserie som oppsummerer hva som skjedde i frontend-verden i uken som var.»


Lokal språkmodell i Google Chrome 148 🤖
Forrige uke lanserte Google versjon 148 av Chrome, og den mest oppsiktsvekkende nyheten er at nettleseren kommer med en innebygd språkmodell. Med det nye Prompt API-et får utviklere direkte tilgang til Gemini Nano, Googles kompakte språkmodell som kjører lokalt på brukerens maskin!
For å bruke APIet må du sette følgende flagg til Enabled i Chrome-instillingene dine:
-
chrome://flags/#optimization-guide-on-device-model chrome://flags/#prompt-api-for-gemini-nano-multimodal-input
Hvis du ikke har gjort det før, må du laste ned modellen i nettleseren:
const session = await LanguageModel.create({
monitor(m) {
m.addEventListener('downloadprogress', (e) => {
console.log(`Downloaded ${e.loaded * 100}%`);
});
},
});Sjekk så om modellen er tilgjengelig:
await LanguageModel.availability() // 'available'Så enkelt var det! Nå er modellen klar til å brukes:
await session.prompt('What do you think of the ForrigeUke article series?')
/**
`You're likely referring to the "Førrige Uke" (Last Week) article series from
Norwegian publication *VG*. It's a really interesting concept, and I think it's a
strong one. Here are my thoughts, broken down into pros, cons, and overall impression:` ...
**/Her bør nok Gemini Nano lese seg opp på faglige artikkelserier, men uansett er dette et utrolig kult resultat!
Det er viktig å huske at teknologien fortsatt er ganske utilgjengelig for en gjennomsnittlig internett-bruker. Modellen må lastes ned først, krever minst 22 GB ledig lagringsplass, og trenger enten en GPU med 4 GB VRAM eller en ganske beefy CPU med 16 GB RAM. Dessuten er kontekstvinduet bare på rundt 4'000 input-tokens, og Prompt-APIet støtter foreløpig bare engelsk, japansk og spansk.
Det er derimot en veldig god start, og språkmodeller vil bare utvikle seg til å bli bedre, raskere, og mer effektive. Å ha en lokal modell tilgjengelig i nettleseren vil tillate lokal databehandling, og dermed løse tonnevis av utfordringer knyttet til personvern. Hvis man er litt smart med hvordan man bruker språkmodellen, kan man også få til veldig mye med et lite kontekstvindu.
Personlig er jeg veldig glad i lokale språkmodeller, og jeg har sterk tro på en fremtid hvor vi skriver programvare rundt lokale språkmodeller istedenfor å bruke sentraliserte KI-tjenester i skyen. Modeller som Gemini Nano og Gemma 4 klarer å kjøre på mobiltelefoner, og beviser at lokal KI er innenfor vår rekkevidde.

Chrome 148 | Release notes | Chrome for Developers
CSS में सिर्फ़ नाम वाली कंटेनर क्वेरी, वीडियो और ऑडियो के लिए लेज़ी लोडिंग, और Prompt API.
...men ikke alle er like begeistret over Googles KI-lansering🫣
Alexander Hanff skrev en bloggpost hvor han gikk hardt ut mot utrullingen av Googles lokale språkmodell som brukes av Prompt-APIet. Her løfter han mange gode poeng, for deler av lanseringen til Google var virkelig kritikkverdige.
Modellen ble nemlig lastet ned automatisk på maskinen til flere brukere som oppdaterte til Chrome 148. Hvis de prøvde å slette den, ble den bare lastet ned på nytt. Google argumenterer på sin side at modellen skal brukes til KI-drevet funksjonalitet i nettleseren, og at lokal prosessering kan forbedre personvernet fordi data ikke sendes noe sted.
Hanff påpeker imidlertid at mye av KI-funksjonaliteten i Chrome fortsatt sender data ut av brukerens maskin. Dermed kan den lokale språkmodellen skape en falsk følelse av trygghet. Hvis dataene uansett sendes til Google, har selskapet i praksis bare flyttet deler av prosesseringen over på brukerens maskinvare.
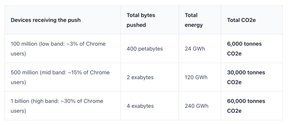
Forøvrig har Google Chrome nesten 4 milliarder brukere, og da kan selv en nedlasting på 4 GB få store miljømessige konsekvenser. Modellen ble riktignok bare rullet ut til brukere med maskinvare kraftig nok til å kjøre den, men Hanff estimerer likevel at mellom 3 og 30 prosent av brukerne fikk modellen lastet ned. Det gir et estimert energiforbruk på opptil 240 GWh. Uansett hvor man står i miljødebatten, er det vanskelig å argumentere for at dette var nødvendig, særlig når mange av maskinene sannsynligvis aldri kommer til å bruke modellen.

Google har også møtt kritikk for å lansere Prompt API-et uten særlig støtte fra resten av nettleserbransjen. Mozilla uttrykte bekymring for at Prompt API-et kan få utviklere til å tilpasse løsningene sine til særegenhetene til Googles modeller, og samtidig tvinge de til å forholde seg til Googles egne retningslinjer og bruksvilkår. WebKit-teamet var i tillegg bekymret for at nettsteder kan ta i bruk den lokale KIen uten tydelig brukersamtykke. Også W3C TAG, som vurderer designet på nye webstandarder, var kritiske til hvor lite gjennomtenkt deler av forslaget fremstod. Kritikken handler derfor ikke bare om selve språkmodellen, men også om at Google har lansert et omfattende API før det fantes bred enighet om hvordan det burde fungere.
Så hva burde Google ha gjort? Hanff mener det viktigste ville vært å spørre brukerne før de lastet ned en stor språkmodell på maskinene deres. I tillegg burde det ha kommet tydelig frem hvilke filer som ble lastet ned, hvor store de var, og hvor de ble lagret på maskinen. Hvis brukere aktivt velger å slette filene, er det dessuten rimelig å anta at de ikke ønsker dem. Da bør slettingen respekteres, og filene burde ikke lastes ned på nytt automatisk.
Alt dette virker kanskje åpenbart, men her har det tydeligvis gått litt fort i svingene for Google. Til tross for den dårlig gjennomtenkte lanseringsstrategien er jeg håpefull for lokale språkmodeller i nettleseren. Om noen år kan det hende vi klarer å standardisere et Prompt-API på en god måte. Kanskje får vi en fremtid hvor brukere selv kan velge og laste ned en lokal KI-modell som kobles til nettleseren, uten at enkeltleverandører som Google trenger å få så mye kontroll.

Google Chrome silently installs a 4 GB AI model on your device without consent. At a billion-device scale the climate costs are insane. — That Privacy Guy!
Google Chrome is downloading a 4 GB Gemini Nano model onto users' machines without consent, with no opt-in, no opt-out short of enterprise ...
safelySetInnerHTML 😇
I en verden langt unna KI-rabalderet, skrev Ahmad Alfy en grundig bloggpost om det nye Sanitizer-APIet til HTML.
Cross-site scripting (XSS) oppstår hovedsakelig på to måter. Den første er stored XSS, hvor en bruker sender inn innhold som lagres i en database eller et CMS, og rendres for andre brukere senere.
// CMS-et returnerer sideinnholdet som HTML
const artikkel = await cms.hentArtikkel(slug);
container.innerHTML = artikkel.html;Hvis en ondsinnet aktør hadde fått tilgang til CMSet, kunne de ha lagt igjen en script-tag som hadde kjørt i nettleseren til alle som besøkte nettsiden.
Den andre typen XSS er reflected XSS. Se for deg kode som viser hva brukeren har søkt etter:
const query = new URLSearchParams(window.location.search).get("q");
heading.innerHTML = `Søkeresultater for ${query}`;Normalt ville dette ha fungert helt fint, for ?q=katter gir "Søkeresultater for katter". Men hvis ondsinnede aktører fikk deg til å klikke på en lenke med ?q=<img src="x" onerror=...>, så kunne de ha kjørt potensielt farlig kode i nettleseren din.
Løsningen har lenge vært å bruke DOMPurify-biblioteket. Men noen ganger kan det faktisk oppstå situasjoner hvor DOMPurify tror HTML-en er trygg, mens nettleseren tolker den på en litt annen måte og likevel finner noe kjørbart. Til syvende og sist er det altså nettleseren som bestemmer hvordan HTML-en faktisk tolkes. Derfor er det bra at den endelig får ansvar for å vaske HTML.
APIet er kjempeenkelt å bruke:
container.setHTML(brukerinnhold);Hvis brukerinnhold inneholder <script>-tagger, farlige attributter som onerror, eller andre potensielt usikre elementer, så vil nettleseren fjerne de før HTML-en rendres.
Det finnes selvfølgelig også en funksjon for de av oss som liker å leve på kanten, og faktisk ønsker å rendre uvasket HTML:
container.setHTMLUnsafe(brukerinnhold);Sanitizer-APIet er fortsatt veldig nytt, og støttes foreløpig bare i utvalgte versjoner av noen få nettlesere. Derfor vil nok neppe DOMPurify dø med det første, men litt som KI i nettleseren, virker dette som enda et steg i riktig retning for web-plattformen. 👣

The HTML Sanitizer API
The HTML Sanitizer API is a new browser feature that helps developers prevent XSS vulnerabilities by safely sanitizing HTML content.

